- AI Minds Newsletter
- Posts
- Where AI is (surprisingly?) headed in 2024...
Where AI is (surprisingly?) headed in 2024...
LLM-integrated Robots are here, Mamba could overtake Transformers, and Computer Vision is the best it's ever been... What's next?
Jose Nicholas Francisco & Marcel Santilli
January 04, 2024
Welcome (back) to AI Minds, a newsletter about the brainy and sometimes zany world of AI, brought to you by the Deepgram editorial team!
In this edition:
📺 Video: Four Reasons AI capacity is exponentially growing in 2024
🤖 Integrating LLMs in Robotic Architecture
🎨 Progress in AI models’ creativity
🎒 Neural Networks and Neurodivergence
🐍 Mamba is the new Transformer?
📈 Mistral 7B versus Llama 2 13B
🐦 On social media: GPT-4 Vision + Mamba Breakdown
🔥 Bonus Content: Mixture of Experts, Audio-tuned LLMs, and GPU Shortages
Thanks for letting us crash your inbox; let’s party. 🎉
Oh yeah, and while you may be familiar with Deepgram’s speech-to-text API, you might want to check out our upcoming text-to-speech technology as well 🥳

🎥 AI capabilities are growing exponentially in 2024, and here’s why
In this video, “AI Explained” presents the argument for the exponential growth of artificial intelligence in 2024. Not only are new models coming out with unprecedented capabilities, but current models are evolving to become much, much more efficient than we initially thought possible in such a short timeframe.
🐎 Robots, Creativity, and Education: Where AI is making further advancements

AI Robots are Here: Integrating LLMs with Robotic Architecture - In this article, Sanusi shows us the history of language interfaces with robots, the current state-of-the-art, and even a few AI x Robotics startups!
Human vs. Machine: A Comparative Study on Creativity in the Age of AI - From art to writing to music, creativity-oriented models grow stronger with each iteration. Likewise, human artists continuously progress as they practice. But what do these growth rates look like? And how do they compare to each other?

Neurodivergence and AI: How Technology Boosts Education - Tools and anthropomorphic robots like Ayoa and Milo help to tailor the learning process for specific needs giving teachers and educators the tools to help their students learn effectively.
🧑🔬 Research Landscape: Where experts say the “cutting-edge” is heading
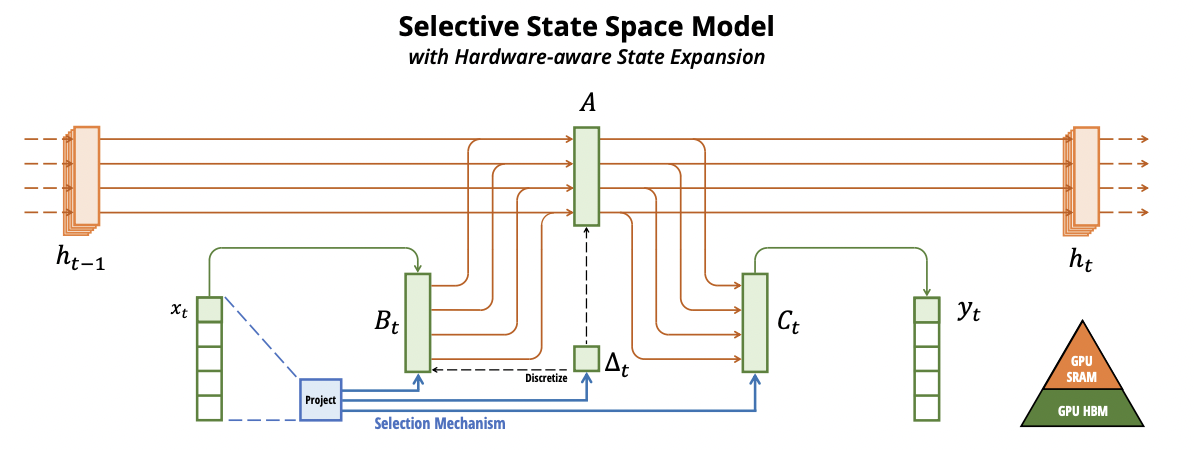
Mamba: Linear-Time Sequence Modeling with Selective State Spaces - As they say in tech interviews: “The current methods work, but can we make them faster?” Well in the case of Transformers, it turns out we can. Here’s Mamba, a “simplified end-to-end neural network architecture without attention or even MLP blocks” that operates in sub-quadratic (in fact, linear) time.
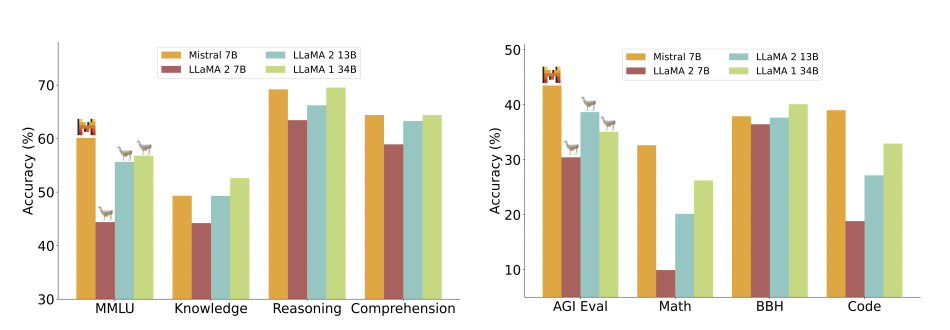
Mistral 7B - This LLM outperforms Llama 2 across all evaluated benchmarks, and Llama 1 in reasoning, mathematics, and code generation… and it does so with over 6 billion fewer parameters.
A new take on an old problem: Handwriting recognition. When we first learn about neural networks, one of the quintessential examples shown is recognizing handwritten digits.
Today, the cutting-edge comes full circle with GPT-4 Vision’s capabilities and this thread, which suggests a way to improve its results (code included!)
Working on auto-applying image transformations to make GPT-4-Vision's handwriting recognition more accurate.
By converting to B&W, sharpening, and heavily adjusting contrast, the results are nearly perfect in terms of text accuracy. twitter.com/i/web/status/1…
— Thomas Frank (@TomFrankly)
8:07 PM • Dec 14, 2023
The Mamba paper mentioned above can be rather intimidating at first glance, so Nathan Labenz comes with some guidance. Check it out!
For Christmas this year, I got you an updated AI worldview!
tl;dr – the new Mamba architecture marks the end of the Transformers Era and the beginning of a new Mixture of Architectures Era, with profound impact
Over 2.5 hours (link below), I cover this from every angle,… twitter.com/i/web/status/1…
— Nathan Labenz (@labenz)
3:07 PM • Dec 22, 2023
🤖 Additional bits and bytes

Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer - “In this work, we address these challenges and finally realize the promise of conditional computation, achieving greater than 1000x improvements in model capacity. . . . On large language modeling and machine translation benchmarks, these models achieve significantly better results than state-of-the-art at lower computational cost.”
How Computing Hardware Drives AI Progress - “The AI boom is now stymied by a formidable roadblock - an acute shortage of Graphics Processing Units (GPUs). The demand for computing has really hockey-sticked, and the shortage of GPUs is bottlenecking innovation progress, especially for smaller startups and researchers.”
In case you missed it: The hidden problem of LLMs! Imagine teaching a child only how to read and write, but never how to speak and listen. That’s what we’re doing with today’s text-based large language models. And in this lightning talk, Jose Francisco discusses a way to combat this issue: an audio-understanding layer.
🐝 Social media buzz